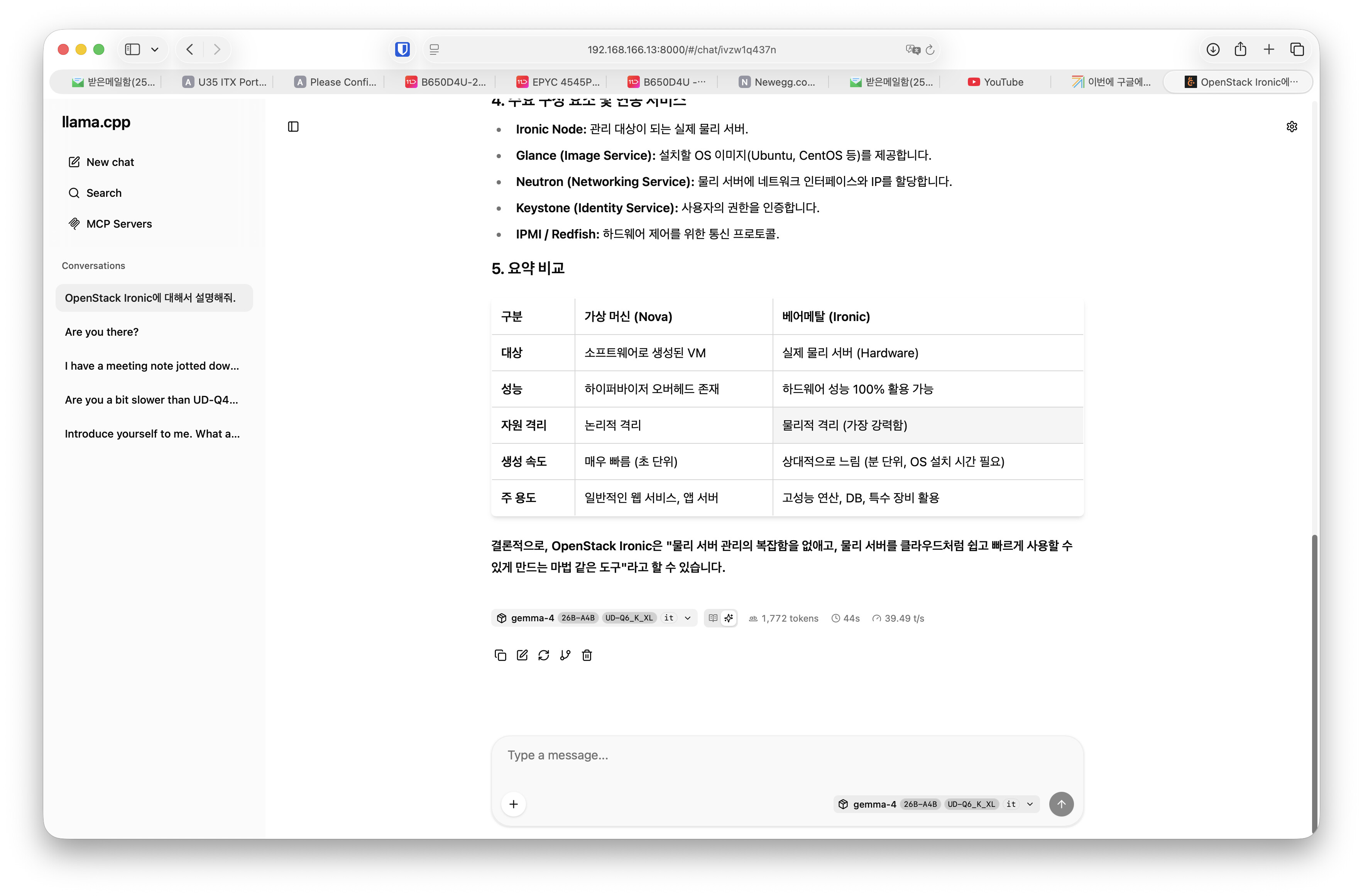
제가 직접 진행하면서 기록했던 내용을 Gemma 4로 다듬어서 공유드려봅니다!
제가 Gemma 4를 구동한 하드웨어는 AMD Ryzen AI 395+ 가 탑재된 (코드명 Strix Halo 라는 이름으로 더 유명하죠) 워크스테이션 입니다. GPU RAM 128GB 입니다.
title: Strix Halo에 Gemma 4 로컬모델 구축하기
date: 2026-04-09
tags: [ytvc,llama.cpp,gemma4,strix halo]
Strix Halo서버에 LLM 배포 가이드 (llama.cpp + ROCm)
이 가이드는 Ubuntu 24.04 환경에서 AMD Strix Halo 하드웨어를 사용하여 llama.cpp를 ROCm과 함께 설정하는 종합적인 절차를 제공합니다. 커널 요구 사항, 통합 메모리(Unified Memory) 설정, ROCm 설치 및 systemd를 이용한 운영 환경 배포 과정을 포함합니다.
1. 사전 준비 및 커널 설정
Strix Halo의 최적 성능과 드라이버 호환성을 위해서는 특정 커널 지원이 필수적입니다.
1.1 OEM 커널 설치
하드웨어 지원을 극대화하기 위해 Ubuntu OEM 커널을 사용합니다.
sudo apt update && sudo apt-get install linux-oem-24.04c
설치 확인: uname -r 명령어를 실행했을 때 6.17.0-xxx-oem과 같은 버전이 출력되어야 합니다.
1.2 ROCm 설치 (AMD GPU 드라이버)
주의: 항상 AMD ROCm Repository에서 최신 버전을 확인하십시오. 2026년 4월 기준으로는 7.2.1 버전 사용을 권장합니다.
-
설치 파일 다운로드:
# 예시: 7.2.1 버전 (최신 URL을 반드시 먼저 확인하세요!) curl -L -O https://repo.radeon.com/amdgpu-install/7.2.1/ubuntu/noble/amdgpu-install_7.2.1.70201-1_all.deb -
설치 패키지 설치:
sudo apt install ./amdgpu-install_7.2.1.70201-1_all.deb -
공식 ROCm 설치 단계 수행:
ROCm Quickstart Guide 또는 상세한 Ubuntu용 패키지 매니저 가이드를 따르십시오.
2. 통합 메모리 설정 (Strix Halo 최적화)
내장 GPU의 성능을 극대화하기 위해, TTM(Translation Table Manager) 설정을 통해 통합 메모리 접근이 가능한 더 큰 메모리 풀을 구성해야 합니다.
2.1 GRUB 설정
BIOS에서 메모리 값을 조정하는 것은 제약이 많으므로, Linux의 GRUB 설정을 통해 직접 페이지 제한을 설정하는 것이 권장됩니다.
-
/etc/default/grub수정:sudo vi /etc/default/grub -
GRUB_CMDLINE_LINUX_DEFAULT업데이트:
IOMMU를 비활성화하고 큰 페이지 제한을 설정하는 파라미터를 추가합니다.GRUB_CMDLINE_LINUX_DEFAULT="amd_iommu=off ttm.pages_limit=25165824 ttm.page_pool_size=25165824" -
변경 사항 적용 및 재부팅:
sudo update-grub2 sudo reboot
2.2 메모리 할당 확인
재부팅 후, 할당된 페이지 용량을 확인합니다.
cat /sys/module/ttm/parameters/p* | awk '{print $1 / (1024 * 1024 / 4)}'
출력값이 기본값보다 증가했는지(예: 96 등) 확인하십시오.
2.3 VRAM/GTT 상태 확인
GPU가 메모리를 올바르게 인식하는지 확인합니다.
sudo dmesg | grep "amdgpu:.*memory"
참고: BIOS에서 설정된 VRAM(예: 512MB 또는 2GB)은 작더라도, GTT(Graphics Translation Table) 항목에서 시스템 메모리의 상당 부분(예: ~98GB)이 사용 가능해야 합니다.
3. llama.cpp 설정 및 실행
3.1 ROCm 사전 빌드 바이너리 다운로드
Strix Halo를 위해 ROCm 7.2에 최적화된 llama.cpp 빌드를 사용합니다.
curl -L -O https://github.com/ggml-org/llama.cpp/releases/download/b8720/llama-b8720-bin-ubuntu-rocm-7.2-x64.tar.gz
3.2 llama.cpp 실행 (수동 테스트)
중요: Strix Halo의 RDNA 3.5 아키텍처를 ROCm 런타임이 인식할 수 있도록 반드시 GFX 버전을 오버라이드해야 합니다.
# HSA_OVERRIDE_GFX_VERSION=11.5.1을 사용하여 호환성을 강제합니다.
HSA_OVERRIDE_GFX_VERSION=11.5.1 ./build/bin/llama-cli -m model.gguf -ngl 99
3.3 모델 다운로드 (예시: Gemma-4)
huggingface-cli를 사용하여 특정 GGUF 양자화 모델을 다운로드합니다.
hf download unsloth/gemma-4-26B-A4B-it-GGUF --local-dir /opt/models/gemma-4-26B-A4B-it-GGUF --include "*UD-Q6_K_XL.gguf"
4. 운영 환경 배포 (systemd)
서버를 백그라운드에서 안정적으로 실행하기 위해 systemd 서비스를 사용합니다.
4.1 디렉토리 구조 설정
시스템 디렉토리를 생성하고 권한을 설정합니다.
sudo mkdir -p /opt/llama.cpp /opt/models /opt/slots/gemma4 /etc/llama.cpp
sudo chown tokdosirak:tokdosirak -R /opt/llama.cpp /opt/models /opt/slots
4.2 서비스 파일 생성
/etc/systemd/system/llama-server.service 파일을 생성합니다.
[Unit]
Description=llama.cpp Server (ROCm - Strix Halo)
After=network.target
[Service]
Type=simple
User=tokdosirak
WorkingDirectory=/opt/llama.cpp
ExecStart=/opt/llama.cpp/llama-server \
--host 192.168.166.13 \
--port 8000 \
--models-dir /opt/models \
--models-preset /etc/llama.cpp/models.ini
Restart=always
RestartSec=5
# --- Strix Halo를 위한 필수 환경 변수 ---
Environment=PYTHONUNBUFFERED=1
# ROCm 런타임이 RDNA 3.5 CU를 인식하도록 강제합니다.
Environment=HSA_OVERRIDE_GFX_VERSION=11.5.1
# 선택 사항: iGPU가 기본적으로 잡히지 않을 경우 사용
Environment=ROCR_VISIBLE_DEVICES=0
[Install]
WantedBy=multi-user.target
4.3 모델 프리셋 (models.ini) 설정
서버 명령어를 간소화하기 위해 /etc/llama.cpp/models.ini에 모델 파라미터를 구성합니다.
Gemma-4 설정 예시:
[gemma-4-26B-A4B-it-UD-Q6_K_XL]
model = /opt/models/gemma-4-26B-A4B-it-GGUF/gemma-4-26B-A4B-it-UD-Q6_K_XL.gguf
slot-save-path = /opt/slots/gemma4/
# Hardware & GPU
ngl = 100
fa = on
threads = 16
batch-size = 2048
ubatch-size = 512
no-mmap = true
# Context & KV Cache (128GB RAM 기준 최적화)
c = 81920
ctk = q8_0
ctv = q8_0
# Sampling
temp = 0.3
min-p = 0.05
repeat-penalty = 1.1
top-k = 40
top-p = 0.95
# Features
jinja = true
embedding = true
4.4 서비스 시작
sudo systemctl daemon-reload
sudo systemctl enable llama-server
sudo systemctl start llama-server
sudo systemctl status llama-server